Documentation
Handler: HTTP reverse proxy
This handler is one of the most demanded features of Cherokee. It dispatches in-bound network traffic to a set of servers, and presents a single interface to the requesters. This is particularly useful to load balance a cluster of webservers at a much higher network stack level than the one allowed by a generic balancer.
All connections coming from the Internet addressed to one of the Web servers are routed through the proxy, which can either deal with the request or pass it (with or without modifications) to the other web servers.
The reverse proxy can do several interesting things besides simply load balancing. It can rewrite headers, and it can try to establish keep-alive connections with every system interfacing with it. That is, it doesn’t matter if all the clients requesting contents from our publicly available Reverse Proxy do not support this feature: the Keep-Alive connections can still be kept within the local pool, greatly improving performance.
Cherokee’s HTTP Reverse proxy is a powerful and modern implementation that also provides X-Sendfile and X-Accel-Redirect. These headers are automatically handled by the server and there is no need to manually specify anything for this functionality to work. Both X-Sendfile and X-Accel-Redirect work in the same way, so there are no artificial restrictions in place. The X-Sendfile/X-Accel-Redirect features work with any kind of object, not only static files, so dynamically generated contents are not a problem at all.
The task of the reverse proxy can be summarized in the following steps.
-
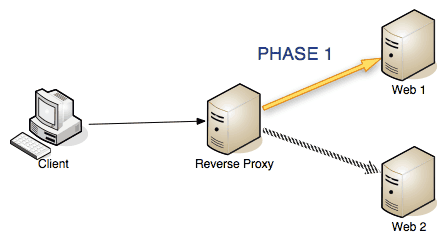
Phase 1: The proxy receives a request, adds the necessary HTTP headers and rewrites the existing ones according to the specified rules. It then dispatches the request to one of the machines in the pool of specified information sources.
Phase 1
-
Phase 2: Once the server that has received the request sends back the response, the reverse proxy deletes the unnecessary return HTTP headers and sends the response back to the requesting client.
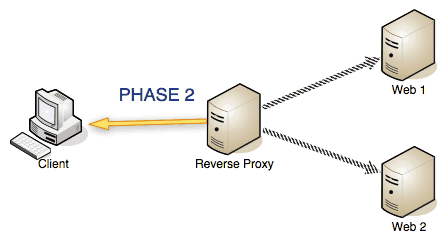
Phase 2
To use the HTTP reverse proxy handler you simply have to specify several parameters. First define a series of information sources. Those will be the ones handling the requests in the end.
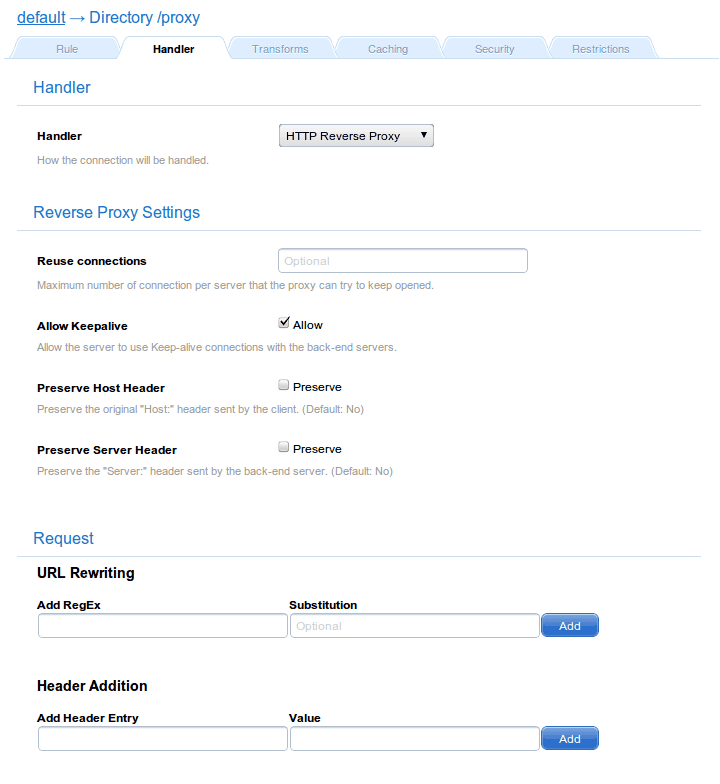
Then you will have to specify the Reverse Proxy Settings by adjusting the following settings.
Handler
-
Reuse connections: the maximum number of connections per server to be kept with Keep-alive. If not specified, the default value of 16 will be taken.
-
Allow Keepalive: Allow the server to use Keep-alive connections with the back-end servers, which is a good idea.
-
Preserve Host Header: Preserve the original "Host:" header sent by the client. It defaults to no, but it is of use in scenarios where you need to uniquely identify a proxied machine. In these cases, IP and port might not be enough, particularly if you are proxying a server on a different port of that which it uses by default. For example, when proxying a Java Server on the same machine through port 80, resorting to the host header will most likely make things work as expected.
-
Preserve Server Header: Preserve the "Server:" header sent by the back-end server. As before, it default to no, but the mechanism is completely analogous.
-
Use VServer error handler: Whenever an error response is received from a back-end server, use the error handler defined for the virtual server to handle it.
Request / Reply
These setting apply respectively to the HTTP request or response.
-
URL rewriting rules, which are specified using regular expressions to modify URLs before relaying the requests.
-
Header additions: to add specific HTTP headers.
-
Hidden returned headers: to eliminate specific HTTP headers.
Back-end Servers
-
Balancer: the type of load balancing strategy to be used to dispatch connections.
-
Information sources: where you will assign the previously defined sources, which are all the servers from the set to be used in the cluster of web servers.
Reverse Proxy